-
Oracle Memory Model
Oracle 의 주요 특징 중 하나가 SGA내에shared pool이란 structure를 도입한 것이다. shared pool을 잘 이해하고 관리하는 것은 Oracle을 사용하는데 있어서 성능 향상 및 문제 발생시 해결에 많은 도움이 된다. 이 shared pool을 이해하기 위해 먼저 Oracle의 memory structure를 살펴본다.
Oracle이 가장 많이 사용되고 있는 운영체제인 Unix에서의 Oracle관련 memory 형태를 간단하게 살펴보면 다음 [그림 1]과 같이 표현할 수 있다.

[그림 1]
이 그림에서 보면, 가장 아래 level은 실제 program의 compiled code이다. 그리고 가장 위 address 부분은 process의 어느 부분을 처리하고 있는지를 제어하는 process call stack 부분이다. 그 중간 부분이 실제 process가 작업하면서 필요한 데이타를 저장하고 찾아오는 부분이라 할 수 있다. 이 장에서는 이러한 Oracle의 memory 구조에 대해서 간단히 살펴보고 다음 장에서 그 중 shared pool 부분, 특히 library cache부분에 대해서 자세히 살펴보도록 한다.
-
Physical Memory Structures
-
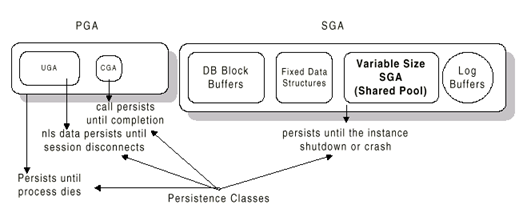
PGA
-
-
process global area 혹은 private global area
-
process당 하나만이 할당된다.
-
다른 process에 의해서는 접근이 불가능하다. 즉 user process에서는 접근이 불가능하고, 대응하는 server process에 의해서만 사용되기 때문에 data structure의 무결성 및 보안이 유지된다.
-
malloc (unix)과 같은 system call을 이용하여 run time때 동적으로 늘어난다.
-
process가 kill되면 해당하는 PGA는 OS에 반환된다.
-
SGA
-
system global area 혹은 shared global area
-
instance내의 모든 process에 의해 사용가능하다.
-
하나의 process에 의해 변경된 부분은 다른 process에 의해서 즉시 보여진다.
-
SGA내의 각 page는 instance내의 모든 process에서 같은 주소로 mapping되기 때문에, 절대적인 주소로 point하는 것이 가능하다.
-
instance startup시에 생성되어서, shutdown시까지 존재한다.
-
일단 생성되면, 고정된 크기를 가진다.
-
SGA가 이렇게 공유되기 때문에 SGA memory에 대한 접근은 동기화되어져야 하고 복구가능하여야 한다. 이러한 synchronization과 recovery는 latch, enqueue그리고 state objects에 의해 구현되어졌다.
-
일부 OS에는 SGA의 maximum size 제한 (예를 들어 HP의 경우 32bit용은 1.75G, 64bit용은 16G)이 있다.
-
-
Logical memory structure
물리적으로 shared memory부분에 할당되는 SGA와 OS Heap 부분에 할당되는 PGA memory부분에 다시 논리적으로 다른 목적으로 사용되는 memory를 구분지을 수 있다. 아래에 그 각각을 설명하였으며, 아래 [그림 2]에서 간단히 나타내었다.

[그림 2]
-
Stack Memory
PGA부분에 속하는 것으로, stack 즉 나중에 저장된 data가 먼저 읽히는 형태의 메모리를 빠르게 할당하기 위해 제공된다. 많은 platform에서 프로그램의 argument나 그 외 일시적으로 데이타를 저장하기 위해 빠르게 할당된다.
-
Call Global Area (CGA)
이 부분도 PGA에 속하게 되며, Program Interface Call (PGI)과 같은 lifetime을 갖는다.
이것은 하나의 call내에서만 필요한 계산을 위해 일시적으로 필요한 부분이다. 그러므로 각 Program Interface Call (UPI/OPI)이 끝나면 해당하는 CGA도 반환된다.
-
User Global Area (UGA)
UGA는 session당 할당되는 것으로써 session 및 user 정보를 유지하며, MTS인 경우에는 SGA에 dedicated connection인 경우에는 PGA에 물리적으로 위치한다. 한 순간에 하나의 process만이 접근 가능하기 때문에 동기화나 recovery는 필요하지 않다.
[참고] sort_area_size
MTS인 경우 User Global Area (UGA)부분은 shared pool (Oracle7)에 할당되고 dedicated인 경우에는 private memory에 할당된다. sort area는 이 UGA부분에 할당되며, sort_area_size parameter는 하나의 sorting 작업을 위해 필요한 real memory의 최대 크기를 나타낸다.
이 sort area는 malloc function을 이용하여 필요한 sort가 완전히 수행될 수 있는 크기 혹은 SROT_AREA_SIZE에 지정된 크기 중 하나에 만족할 때까지 점차적으로 늘어난다.
한 process에서 하나의 sorting이 끝나면, 다음의 sorting을 위하여 sort_area__retained_size으로 줄어들게 된다. 기본적으로 이 sort_area_size과 sort_area__retained_size은 같은 값을 가지는데, MTS인 경우 혹은 매우 큰 sorting작업인 경우 sort_area__retained_size을 적당하게 작게 하여 process가 종료되기 전에 sorting에서 사용된 memory를 일부분 해제하도록 하게 된다.
(주의) UNIX system의 dedicated connection인 경우 sort_area__retained_size이 sort_area_size보다 작은 경우 실제 release된 memory는 OS에 반환되는 것이 아니라 UGA 부분에 반환하게 된다. 그러므로 반환된 부분을 다른 process가 사용할 수 있는 것은 아니고 자기 process만이 사용가능하게 되어 실제 sort_area_size이 매우 크고, sort_area__retained_size가 작은 경우, sorting작업은 끝났음에도 불구하고 performance에 심각한 영향을 주는 경우도 발생하고 있다. (Bug:566708참조, status:not a bug)
-
Process Global Area (PGA)
physical memory에서 기술한 것과 같다.
-
Shared Global Area (SGA)
physical memory에서 기술한 것과 같다.
-
-
CLASSES
Oracle operation은 자신이 사용하는 data를 물리적으로 SGA나 PGA에 저장한다. 이때 어느 memory부분에 data를 위치시킬 것인지는 첫째, 그 data가 private인지 public인지에 따라 다르고, 둘째로는 그 data가 필요한 기간에 따라 다르다. 이 기간이라는 것은 lifetime으로 표현이 되며 call, session, process, instance로 나눌 수 있다.
-
call: call lifetime은 Oracle Programmatic Interface (OPI) call을 수행하는 동안이다. 이러한 call을 수행하는 동안 필요한 memory는 PGA부분에 위치하게 되며, 특별히 CGA라고 부른다. 이 CGA부분에 속하는 것은 DDL이나 DML operation에서 일시적으로 필요한 계산, 혹은 PLSQL에서 local 변수 등이다.
-
session: session의 lifetime은 client가 database에 접속하면서부터 연결을 끊을 때까지이다. 예를 들어, NLS parameter, optimizer goal, sql_trace 등 alter session 문장으로 지정 가능한 데이타 등이 이 class에 속한다. 이러한 data들이 저장되는 공간을 UGA라고 부른다.
-
process: process의 lifetime은 process가 시작해서 없어질 때까지 지속된다. process lifetime동안 필요한 data는 shared, public 모두 가능하며, 일반적으로 CGA, PGA, UGA 를 필요로 하는 private인 경우가 많다.
-
instance: instance의 lifetime은 startup nomount상태에서 db가 shutdown될 때까지이다. instance lifetime동안 필요한 data는 일반적으로 public으로 볼 수 있으며, buffer cache, log buffer, shared pool 등 주로 SGA 부분을 차지한다.
위의 구분은 call, session, process, transaction, system state로 구분되는 state objects와도 관련이 있다. 이러한 state objects는 각 state object마다 연결되는 database entity들이 존재하며, fail인 경우에는 이 resource들을 clean하기 위해 PMON이 이용된다.
-
HEAPS
모든 동적으로 할당되는 메모리 부분은 heap manager에 의해 관리된다. heap manager는 ‘heap’이라고 불리는 메모리의 논리적인 집합을 할당/해제하게 된다. heap이란 deap descriptor와 extent라고 불리는 메모리 조각의 집합으로 구성되며, 각 extent는 연속된 메모리 조각이다.
-
Memory Allocation
각 heap은 비어 있는 memory의 chunk들의 list를 가지고 있다. user가 일정한 크기의 memory chunk를 요청하면, heap manager가 heap의 free chunk 중에서 요청한 크기이상이 되는 것을 찾는다. 일단 찾으면 필요한 부분만 잘라서 user에게 할당해 주고, 나머지 부분은 다시 free list에 들어간다. 남은 chuck가 일정 크기 이하로 작아질 경우라면, fragmentation을 막기위해 자르지 않는다.
-
Multiple Free Lists
heap을 생성할 때, 내부적으로 heap이 multiple free list를 가지도록 지정할 수 있다. 또한 각 heap이 몇개의 free list를 가지고 각 list는 어떤 범위의 크기의 chunk를 가질지도 지정가능하다. 이렇게 multiple free list를 가진 heap으로부터 space를 할당받을 때는, 각 list에서 chunk를 찾을 때 binary search를 이용하여, 탐색 시간을 줄인다.
-
Flexible Allocation
memory를 할당받고자 할 때는 요청 크기와, 최소 크기를 parameter값으로 전달한다. 일단, 요청한 크기의 memory를 찾는데, 만약 없으면 최소 크기를 포함하는 메모리를 할당받게 된다. 이렇게 하여 memory가 조각이 나더라도 운영이 되도록 한다.
-
Fee
만약 할당된 chunk가 해제되면, 이것은 인접한 다른 free chunk들과 merge한 후 free list에 등록시킨다.
-
Permanent Memory
일단 할당된 후 절대 해제되지 않는 memory를 permanent memory라고 하는데, 각 heap descriptor는 이러한 permanent chunk 부분을 가리키는 pointer를 가지고 있다. 이 permanent chunk는 두 부분으로 나누어지는데 앞부분은 이미 permanent로 할당된 memory 부분이고, 뒷부분은 아직 할당되지 않은 reserved area이다. chunk의 header에는 어느 부분부터가 reserved area의 시작인지를 가리키는 pointer가 있다. heap으로부터 permanent memory를 할당할 때에는 reserved area가 요청한 크기를 만족할 만큼 큰지를 확인한 다음, 충분하면 reserved area의 시작을 가리키는 pointer를 필요한 크기만큼 할당한 뒤로 옮기고, 그렇지 않으면 현재의 reserved area는 해제하고 다른 충분히 큰 permanent chunk가 할당된다.
실제 permanent memory는 heap자체가 해제되면 그 부분도 해제된다. 이 외에도 mark and restore 방법을 통해 해제되기도 한다.
-
Recreatable Chunk
memory chunk가 heap에 할당될 때, chunk의 내용이 재생성가능한 것으로 명시할 수 있다. 이러한 option으로 생성되면, 이 chunk는 사용 중이지 않을 때 명시적으로 ‘unpinned’될 수 있다. 사용자가 heap으로부터 space를 요청할 때 공간이 없으면, 이러한 unpinned 혹은 recreatable chunk를 해제하고 사용할 수 있다. unpinned chunk는 LRU list에 존재하게 되어 무엇을 가장 먼저 비게 할 것인지 결정할 수 있으며, 이러한 방법은 row cache나 library cache에 이용된다.
-
Extents
연속된 chunk들의 집합을 extent라고 불리며 이 extent들이 heap을 구성한다. heap에서 chunk를 요청하면, heap manager는 heap에 포함되어 있는 extent들의 집합 안에서 요청한 크기의 조각을 할당 받으려고 한다. 만약 이때 발견하지 못하면, heap manager는 새로운 extent를 요청하여 이것을 heap에 추가한다.
만약 한 heap의 extent들이 다른 heap으로부터 할당되었다면, 이 heap은 다른 heap의 ‘subheap’이라고 한다. ‘subheap’은 다음과 같은 용도를 제공한다.
-
parent heap에서 작은 chunk를 할당하는 대신 subheap을 할당하여 parent heap의 fragmentation을 줄여준다.
-
permanent memory 부분만을 subheap으로 별도로 관리가능하다.
-
heap의 일부분만 해제할 필요가 있을 때, subheap으로 할당하면 쉽게 해제 가능하다.
-
subheap이 하나의 process에 의해서 사용된다면, latch를 사용할 필요가 없다.
subheap은 parent heap과 관계없이 pin되고 unpin될 수 있다. subheap이 unpin되면, parent heap은 subheap 의 extent를 해제하도록 요청할 수 있다. 이때 사용되지 않은 extent가 전혀 없다면, heap은 subheap의 owner에게 전체 subheap을 해제하도록 요청한다. 이러한 방법으로 subheap이 다른 recreatable space의 chunk처럼 보이게 한다.
실제 subheap의 일부분이 비어지게 되면, 그 빈 부분은 이후에 그 subheap만이 사용가능하고, parent heap도 사용하지 못한다. 이러한 문제는 많은 memory 부분을 낭비하도록 하기 때문에 현재 사용하지 않고 비어 있는 부분을 parent heap에 반환하도록 하는 call이 존재한다.
-
Recovery
heap의 space는 공유될 수 있기 대문에, heap manager는 heap에 대한 사용을 동기화하고, heap의 상태를 변경 중 죽은 process에 의해 일관되지 않은 상태로 남은 부분을 복구시키는 기능을 가지고 있어야 한다. heap이 생성될 때, ‘recoverable’로 지정되면, 이것이 concurrency control과 recovery 요구되는 heap임을 나타낸다. concurrent control을 구현하기 위해서는 heap의 상태를 변경하기 전에 latch 잡도록 하고, recovery를 위해서는 변경에 대한 이전 사항을 heap에 기록하도록 한다.
private memory에 할당된 heap은 concurrency control이나 recovery가 필요하지 않다. shared memory에 할당된 heap도, 동시에 여러 process가 접근할 필요가 없는 것이라면 concurrency control이나 recovery가 필요하지 않다. 만약 이 heap을 사용하던 process가 비 정상적으로 종료되면, PMON process에 의해서 즉시 해제된다. 이러한 heap으로는 UGA가 대표적인 경우이다. 이러한 shared memory내의 non-recoverable heap은 반드시 recoverable parent heap을 가져야 한다.
-
Error Checking
heap manager는 heap에 대해 요청 시 error checking작업을 수행한다. 아래에 그 중요한 것을 정리하였다.
-
-
각 chunk의 header내에 있는 magic number를 check하여 chunk가 overwrite되었는지 검사한다.
-
모든 chunk가 list에 바르게 들어있는지 확인하기 위해서 free list를 검사한다.
-
각 chunk의 길이를 검사한다.
-
extent의 header를 검사한다.
heap에 대한 check는 event (10235)를 사용하여도 이루어질 수 있다.
-
Memory Protection
unix와 같은 운영 체제에서는 memory의 일정 부분에 대해서 일기/쓰기에 대해 제한할 수있다. 이것은 주로 운영 체제의 page 단위로 가능한데 heap manager는 이러한 기능의 이점을 이용할 수 있는 interface를 제공한다.
memory chunk를 하나의 page에 위치시킬 수 있는 option을 이용하여 다음과 같은 제한적 접근 방법을 제공한다.
-
모든 접근을 막는다.
-
read는 가능하고 write는 막는다.
-
read, write 모두 가능하게 한다.
heap은 또한 모든 extents를 하나의 page에 위치시키도록 할 수도 있는데, 이렇게 하면 heap의 모든 extent에 대해서 접근을 제한할 수 있다.
-
BOOTSTRAPPING
SGA, PGA, 혹은 UGA가 할당될 때 memory를 초기화하고 할당하기 위해 호출되는 routine이 필요하다. 이 notifier routine에 flag를 전달하여 어떤 종류의 memory가 초기화되어야하고, 할당되어져야 하는지를 알려준다.
이렇게 메모리가 초기화되고 할당되는 순서가 중요한 경우가 많은데 먼저, instance가 startup될 때는 다음의 순서와 같다.
-
fixed PGA가 할당되고, 이것을 초기화하기 위해 notifier가 호출된다. 여기에서 fixed PGA란 모든 PGA variable들의 집합을 말한다.
-
notifier가 호출되어 init.ora file내의 parameter를 이용하여 필요한 SGA size를 계산한다.
-
SGA가 생성되고 process에 mapping된다.
-
notifier가 SGA를 초기화한다. 이 시점에서 SGA heap으로부터 SGA memory를 할당하고 fixed SGA에 이 memory에 대한 pointer를 저장한다.
-
PGA를 초기화시킨다. 이 때 PGA heap으로부터 PGA memory를 할당하고 fixed PGA에 이 memory에 대한 pointer를 저장한다.
이미 start되어 있는 instance에 접속하기 위한 순서는 다음과 같다.
-
fixed PGA가 할당되고 notifier가 호출되어 PGA를 초기화시킨다.
-
SGA가 process의 address space에 mapping된다.
-
PGA를 초기화하기 위해 notifier가 호출된다. 이 때 PGA heap으로부터 PGA가 할당되고, 이 부분에 대한 pointer가 fixed PGA에 저장된다.
-
여기에서 중요한 것은 PGA가 초기화되기전에 먼저 SGA가 항상 사용가능하고 초기화되어 있어야 하며, 그 역은 성립하지 않는다는 것이다.
-
-
Library Cache Manager
heap manager(KGH)는 메모리 할당과 해제를 모두 담당한다. Library cache manager는 이 heap manager의 client로서, library cache object를 제어하고 관리한다. 즉, library cache manager가 library cache object를 관리하다 메모리가 더 필요하면 heap manager를 요청하는 등 shared pool을 관리하고 조작하기 위해서는 heap manager와 library cache manager가 함께 작업해야 한다.
library cache의 가장 중요한 목적은 library cache를 빠르게 찾고 저장시키는 기법을 제공하는 것인데 그 목적을 위해 HASHING 기법을 이용한다. 이 hashing기법을 이용하여 object에 대한 identity(name)을 포함하고 있는 HANDLE을 찾아내며, library cache handle은 다시 library cache object를 가리키고 있다.
-
hash table and hash bucket
hash table은 hash bucket들로 구성되어 있고 hash bucket의 초기 갯수는 509개이다. 이 bucket이 꽉 차면 (실제로는 평균적으로 하나의 bucket에 복수개의 handle이 할당되어지면) bucket의 수가 늘어나서 다음 prime number만큼 된다. 즉 509, 1021, 2039와 같은 순서로 늘어나며, 이렇게 bucket의 수가 한번 늘어나면 기존의 table에 존재하던 library cache object들도 새로운 table에 새로운 hashing을 이용하여 재배치된다. 이러한 작업은 실제 매우 드물고 짧은 시간(3 ~ 5초간)동안만 library cache의 접근을 막는 큰 부하를 주지 않는 작업이다. 이렇게 늘어난 hash table은 줄어들지는 않는다.
[참고] _kgl_bucket_count
초기 bucket의 수는 _kgl_bucket_count라는 hidden parameter에 의해서 변경되어 질 수 있으며, 실제 이 값을 바꾸는 것은 대부분 불필요하나, 매우 많은 object를 사용하는 경우에는 아래 [표 1]과 같이 변경하는 것이 도움이 된다. bug381193(fixed in 8.0.2)을 참조해보면 실제 이것이 ora-600[17033]에 대한 workaround가 되기도 한다.
_KGL_BUCKET_COUNT의 값
0
1
2
3
4
5
6
7
8
bucket의 갯수
509
1021
2039
4093
8191
16381
32749
65521
131071
[표 1]
library cache manager는 다음과 같은 절차를 통해 object를 찾는다.
-
주어진 object의 namespace, object name, owner, database link값을 이용하여 나머지를 구하는 modulo hash function을 적용하여 object가 존재하는 hash bucket을 찾아낸다.
[참고] sql 문장의 경우 앞, 뒤 64 bytes의 글자를 이용하다.
-
hash bucket을 찾은 다음 linked list를 따라 object가 존재하는지를 check한다.
-
만약 object가 존재한다면 (9)로 가고, 존재하지 않는다면 library cache manager는 주어진 이름으로 empty object를 생성한다.
-
(3)에서 생성된 empty object를 hash table에 포함시킨다.
-
client 에게 object를 load하도록 요청한다.
-
client가 disk에서 읽어 object를 찾는다.
-
heap manager에게 memory를 할당하도록 요청한다.
-
object를 load한다.
-
찾은 object를 사용한다.

[그림 3]
-
-
Library Cache Handle
library cache handle은 library cache object를 가리키고 있으며, library cache object의 이름, namespace, timespace, reference list, object를 locking하고 있는 lock list, pinning 하고 있는 pin list를 포함하고 있다.
library cache manager는 anonymous PL/SQL block을 포함한 모든 object에 이름을 붙인다. 이 이름은 object의 owner, database link이름과 link의 owner로 구성되어지며, 같은 namespace안에서는 유일한 이름을 가지게 된다. namespace는 library cache object를 유형별로 나누기 위해 사용되어진다. v$librarycache view를 통해 이 namespace를 확인할 수 있는데 다음과 같은 종류가 있다.
-
SQL AREA (SQL cursor)
-
TABLE/PROCEDURE (view, synonym, sequence 등 포함)
-
BODY
-
TRIGGER
-
INDEX
-
CLUSTER
-
OBJECT (PL/SQ anonymous block)
-
PIPE
handle은 현재 자신을 참조하고 있는 reference가 하나도 없고, memory내에 ‘KEEP’하도록 mark되지 않았다면 free되어질 수 있다.
-
Library Cache Object
library cache 는 다음과 같은 종류의 library objects를 가지고 있다. 여기에서 shared cursors란 sql문장을 나타내는데, 단 ddl 및 alter system문장은 사용되고 바로 memory에서 flush되어 library cache에 남아있지 않는다.
-
packages
-
procedures
-
functions
-
trigger
-
shared cursors
-
anonymous PL/SQL blocks
-
table definitions
-
view definitions
-
form definitions
위에서 나열한 library cache object는 여러개의 part의 구성되어지는데 그 중 dependency table, child table, authorization table, type, status flag, data block에 대해 간단히 살펴본다.

[그림 4]
-
dependency table
dependency table은 자신이 dependent하고 있는 다른 library cache object들을 가리킨다. 예를 들어 어떤 procedure내에 여러개의 table에 대한 operation을 포함하고 있다면 이 procedure의 dependency table은 이러한 dependent handles(tables)을 포함한다. 이러한 dependency 정보는 DBA_DEPENDENCIES, V$OBJECT_DEPENDENCY view를 통해 확인해 볼 수 있다.
object의 구조가 변경되어 timestamp가 변경되거나 object가 drop되는 등의 변경이 발생하면 이 object에 대한 모든 dependency references가 invalidate된다.
-
child table
child table은 text상으로는 같은 다른 version의 library cache object를 가리킨다. 이렇게 모든 child object들은 text상으로는 완전히 일치하기 때문에 hash table에서의 각 child reference는 parent object로부터의 상대적인 위치에 의해 reference며, name을 가지고 직접 reference할 수는 없다.
예를 들어 서로 다른 두 user가 ‘SELECT * FROM DEPT’라는 문장을 수행하면, 이 두 문장은 text상으로는 일치하나 DEPT는 각 user가 가지고 있는 서로 다른 DEPT table을 나타낸다. hash table은 SQL문장 자체의 text를 hash function을 이용하는데 두 user모두 이 문장을 이름으로 가진 parent object를 통해 object에 접근하게 된다.
-
authorization table
이 table은 library object에 부여된 권한을 포함한다.
-
type
ORACLE7에서는 다음과 같은 type이 존재하며, 이후 추가될 것이다.shared cursor(SQL cursor, PL/SQL anonymous block), index, table, cluster, view, synonym, sequence, procedure, function, package, table, package body, trigger
[참고] v$db_object_cache의 type
v$db_object_cache에는 shared cursor (v$sqlarea참고)를 제외한 library cache object에 대한 정보가 들어있다. 이 view중 type column에 table, index, view, procedure등 여기에서 설명한 type에 대한 정보가 나타난다. 그런데 실제 이 type외에 ‘NON-EXISTENT’와 ‘NOT LOADED’라는 두가지 value가 더 나타난다. 이 두가지 type은 다음과 같은 의미를 지닌다.
-
-
NON-EXISTENT: 존재하지 않는 object라는 이 표현은 실제 같은 이름의 object가 생성되면 그 의미가 변경되는 경우에 해당한다.
예를 들어 scott.dept에 대해서 dept라는 public synonym을 system이 만든 후 모든 user에게 select권한을 주었고, eykim user가 ‘SELECT * FROM DEPT’라는 문장을 수행하게 되면 이 v$db_object_cache에 NON-EXISTENT type을 가진 dept object가 eykim user로 생성되어 있는것을 확인할 수 있다. 이 후 만약 eykim user가 dept 라는 table을 만들고 다시 같은 문장인 ‘SELECT * FROM DEPT’를 수행하면 이때는 scott.dept가 아닌 eykim.dept를 select하는 것이며 v$db_object_cache에도 type이 TABLE로 변경된다.
-
NOT LOADED: library object가 일단 memory에 load되었다가 그 object에 대한 대부분의 사항이 memory에서 flush된 경우이다. 즉 library cache descriptor(handle)은 남아있으나 실제 library cache object에 대한 모든 내용은 memory에 남아있지 않은 상태이다.
-
status flags
library cache object의 상태를 나타내는 status flag는 다음과 같은 종류가 있다.
existent, non-existent, locally represented, being created, being altered, being dropped, being updated,
-
KGL data blocks
하나의 object당 최대 8개의 KGL data block이 있으며, 각 object마다 control block이 있어서 이 control block내의 heap descriptor가 diana tree, p-code, source code, shared cursor context area등 8가지 종류의 KGL data block중 필요한 부분을 가리키게 된다.
각 data control block에는 heap pin count라는 값이 있어서 이 값이 1이상이면 heap에서 free시킬 수 없다. pin된 library cache object 내의 heap들은 다시 별도로 pin되고 load되어진다.
그림에서 볼 수 있듯이 하나의 library cache object가 8개의 heap이나 subheap으로 구성되어질 수 있지만, 반드시 8개 모두 할당되어야 하는 것은 아니다. PL/SQL의 경우 common object information heap, source heap, diana heap, p-code heap, m-code heap, herror heap 이렇게 6개의 heap을 주로 사용한다. 이 각각은 다음과 같은 내용을 포함하고 있다.
-
common object information heap:global name, dependency list, security list, 그 외 object에 대한 정보
-
source heap: PL/SQL source
-
diana: parse와 syntax tree, meta data에 대한 기술 등
이 diana에 의해서 PL/SQL program 의 size제한이 생기게 된다.
[참고] PL/SQL program unit의 크기 제한
Oracle은 diana를 구성하는 tree의 node의 갯수를 program unit마다 다음과 같이 제한하고 있다. 7.0.15 이전 version까지는 source code자체가 64K 까지만 가능했지만, 7.0.15 version부터는 이 제한은 없어지는 대신 diana의 node 갯수의 제한으로 인해 결국 program의 source에 제한이 생긴다. iana node의 갯수의 limit은 oracle version별로 다음과 같다.
-
~ 7.2: 16K
-
7.3 & 8.0: 32K
-
8.1: 64M (package body와 type body), 나머지 unit에 대해서는 32K
이 제한은 각 program unit마다의 제한이므로 실제 제한에 걸리는 것은 주로 package body이다. 그래서 8.1부터는 이 package body나 type body에 대해서는 64M갯수로 늘렸다.
tree node를 구성하는 것은 identifier, keyword, operator등인데, 이러한 글자들의 길이가 예를 들어 4 byte정도 된다면, 실제 source code의 제한은 이 node갯수 *4가 되어 7.3같은 경우 128K 정도가 되는 것이다. 물론 각 identifier나 operator를 긴 글자를 이용하였다면 이 크기는 더 커질수도 있다.
이 diana의 크기를 나타내는 것이 dba_object_size의 view의 parsed_size인데, Oracle7.2부터는 package body나 type body에 대해서는 diana를 disk에 저장하지 않기 때문에 이 값으로 0으로 나온다. 그래서 package body의 크기에 대한 정확한 값은 알 수 없으며, 평균적으로 source code의 한 line당 약 5 ~ 10개의 diana node가 존재하는 것을 참고할 수 있다.
-
-
p-code heap: debugging 정보
[참고] 원래는 portable executable code를 위한 것이었으나, 실제로는 구현되지 못했다. 현재 모든 code는 machine dependent하다.
-
m-code: executable code
[참고] p-code에 portable executable code를 저장하면 이곳에는 machine dependent한 부분만 저장하려고 하였으나 실제 모든 executable code를 모두 포함하고 있다.
-
error heap: compile시 발생하는 오류

[그림 5]
shared SQL문장을 위해서는 그림에서와 같이 두개의 heap이 사용되어진다. 하나는 object information heap이고 다른 하나는 query/execution plan heap이다. object의 source는 이름 자체가 된다.
-
Locking과 Pinning
shared pool상에서 concurrency control을 위해서 lock (latch는 lock의 일종)과 pin이라는 두가지 data structure가 존재한다. lock은 pin보다 윗 level로 handle에 lock을 건 후에만 object를 pin할 수 있다. pin은 object의 내용을 읽거나 변경하기 위해 거는 short-term lock정도로 생각할 수 있다.
-
locks
lock은 handle에만 걸 수 있으며, null, share, exclusive 이렇게 세가지 종류가 존재한다. null 혹은 shared mode는 object를 수행하거나 compile시 참조하는 등 읽고자 할 때 사용되며, exclusive lock은 object를 변경하고자 할 때 필요하다. shared lock과 null lock의 차이점은 shared lock은 다른 client가 share lock이나 exclusive lock을 요청하면 오류를 발생시키는데 반해, null lock은 같은 object에 다른 client가 exclusive mode로 pin하고자 하면 해제된다는 것이다. 예를 들어, read-only object에 null lock을 건 경우, 이 object가 depend하고 있는 parent object에 exclusive pin이 걸리면, read-only object에 걸린 lock은 broken된다.
read-only object에 걸린 모든 lock은 null mode여야 하는데 이것은 object handle을 사용한다는 것을 나타낸다. null lock이 invalidate된 것을 통해, 이 object를 사용하려고 하는 process로 하여금 이 object가 parent object의 변경으로 인해 invalid되었음을 알려 준다.
이러한 lock은 이것이 session이나 transaction 혹은 call과 관계되었는지에 따라 해제되는 시점이 결정된다. session인 경우는 session이 종료될 때 transaction인 경우는 commit이나 rollback될 때까지 call인 경우는 call이 끝날 때까지 유지된다.
-
Pins
library cache object를 locking한 후, process는 그 object를 접근하기 전에 pin하여야 한다. pin에는 shared mode와 exclusive mode, 두 가지가 있는데 이렇게 pin함으로써 어떠한 data block 즉 heap이 load되어 사용되어질 것인지를 나타낸다.
pining과 unpinning을 통해 어떠한 heap이 해제될 수 있는지를 알 수 있다. client가 실제 space를 사용하고 있지 않으면 그 부분은 unpin하여야 하는데, 이후 다른 client가 요청한 내용이 space가 부족한 경우에는 heap manager가 이러한 unpin된 space를 해제하도록 unpin한 client에게 요청할 수 있다.
procedure를 변경하는 예를 들어 lock과 pin을 설명하도록 하자.
-
shared pool내에 load되어 있는 library cache object인 procedure에 exclusive mode로 lock을 건다.
-
이렇게 함으로써 이 object를 drop하거나 replace하는 operation을 막을 수 있고, 이 object를 reference하는 procedure, package, function 등을 생성하지 못하게 한다.
-
이 procedure의 정의와 권한 정보를 얻어 security및 오류 검사를 수행하기 위해 share mode로 pin을 한다.
-
shred pin이 해제되고, exclusive mode로 repin된 후 procedure는 recompile된다.
-
이 object를 reference하는 모든 object들은 invalidate된다.
-
-
library cache latches
latch는 매우 빠르게 잡고 풀 수 있는 lock의 일종이다. lock(enqueue)이 주로 둘 이상의 process가 동시에 같은 data structure를 access하는 것을 막기 위한 것이라면 latch는 동시에 같은 code(oracle source code)부분을 실행하는 것을 막기 위한 것이라고 할 수 있다. latch를 잡고 있는 process가 죽으면 그 latch를 정리하여 주는 cleanup procedure가 호출되며, 각 latch에는 level이 있어서 dead lock이 발생되지 않도록 한다. 즉 어떤 process가 특정 level의 latch를 잡고 있으면 자기보다 낮거나 같은 level의 latch는 다음에 요청할 수 없다. (nowait가 아닌 경우)
library cache latch에는 세가지가 있는데 library cache latch, pin latch, load-lock latch 이렇게 구분 가능하다. library cache latch가 가장 높은 level이며 handle에 lock을 걸기 전에 먼저 library cache latch를 잡아야 한다. heap을 pin하기 위해서는 먼저 library cache pin latch가 필요하고, library cache entry를 load하기 전에는 load lock latch를 얻어야 한다.
초기에는 이러한 latch가 세 종류마다 하나 뿐이어서 contention문제가 많이 발생하였었다. 특히 library cache latch의 경우에는 handle을 hashing하거나, drop혹은 새로운 handle을 생성하는 등의 작업마다 필요하기 때문에 가장 경쟁이 심했었는데 Oracle7.2 이상부터 이러한 문제를 다소 해결하기 위해서 library cache latch를 복수개로 유지하고 있다. 각 latch는 각각에 할당된 object만을 위해 사용되어진다.
-
Shared Pool의 tuning과 monitoring
shared pool에 대한 성능 문제는 기본적으로 shared pool을 충분히 크게 유지하면 해결할 수 있다. 그러나 OS의 shared memory를 사용하는 shared pool은 물리적으로 제한이 있으며, 너무 큰 shared pool은 memory를 낭비하여 user process가 사용해야 하는 memory부분이 부족하게 되는 문제를 야기시킬 수도 있다.
다음에서 shared pool 사용시 발생가능한 문제를 최소화하고 성능을 향상시키기 위한 방법을 알아보도록 한다. 특히 shared pool에 문제를 야기시키는 주요 원인인 fragmentation과 latch contention을 나누어 아래와 같은 순서에 의해 살펴본다.
-
view를 통한 hitratio확인 및 tuning
-
latch contention 확인
-
ORA-4031
-
Object를 shared pool에 KEEP
-
SQL문의 공유
-
PARSING 감소
-
CURSOR_SPACE_FOR_TIME
-
SESSION_CACHED_CUSROS
-
CLOSE_CACHED_OPEN_CURSORS
-
그 외 사항들
-
-
Library Cache의 Tuning
library cache에 대한 작업의 수행 속도를 증가시키기 위해서는 library cache miss를 줄이고, 원하는 sql 문장이나 object들이 가능한 모두 cache되어 있어야 한다.
library cache miss가 발생할 수 있는 단계는 다음과 같이 parse나 execute단계에서 가능하다.
-
Parse: SQL문장을 parsing할 때, 이 문장의 parsing된 형태가 library cache의 shard SQL area내에 존재하지 않으면, Oracle은 이 문장을 parsing한 후 SQL area에 할당한다. 그러므로 parsing단계에서의 library cache miss를 줄이기 위해서는 SQL문장을 최대로 공유하도록 유도하여야 한다.
-
Execute: SQL문장을 execute할 때, 이미 parsing된 code가 다른 문장을 cache시키기 위해 shared pool에서 반환되었다면, Oracle은 내부적으로 그 문장을 다시 parsing하고, shared SQL area를 할당한 후 execute한다. 그러므로 이런 execute단계에서의 miss를 줄이기 위해서는 충분한 공간의 library cache를 확보하여야 한다.
이러한 library cache에 대한 hit/miss 상황을 확인하기 위해서는 V$LIBRARYCACHE view를 참조하면 된다. 이 view를 통해 library cache의 성능 문제를 점검할 수 있으며, 아래와 같은 질의를 통해 각 namespace별로 cache handle과 cache object의 hitratio가 확인가능하다.
SQL> select namespace, gets, gethitratio, pins, pinhitratio, reloads, invalidations
from v$librarycache;
NAMESPACE GETS GETHITRATIO PINS PINHITRATIO RELOADS INVALIDATIONS
————- —— ———– ——- ———— ——– ———-
SQL AREA 59366 .994188593 155363 .995475113 1 11
TABLE/PROCEDURE 3043 .902398948 4699 .930836348 9 0
BODY 52 .557692308 63 .46031746 0 0
TRIGGER 0 1 0 1 0 0
INDEX 21 0 21 0 0 0
CLUSTER 27 444444444 15 .333333333 0 0
OBJECT 0 0 1 1 0 0
PIPE 2 0 2 0 0 0
여기에서 나타난 컬럼 중 중요한 몇가지의 의미를 살펴보면 다음과 같다.
-
gets: library object의 handle을 access한 횟수
-
pins: library cache object가 실제 수행된 횟수
-
reload: execution 단계에서 library cache에 대한 miss가 발생한 횟수
-
invalidations: non-existent library object가 invalidated된 횟수
여기에서 gets나 pins은 큰 값을 가지고, gethitratio와 pinhittratio값이 작다면 (약 85%이하), shared pool의 크기를 늘리거나, 이 문서에 포함될 tuning작업이 필요하다. 위의 실제 결과물에서 볼 수 있듯이 gethitratio나 pinhitratio은 get/pin과 reload의 값으로 계산된 것이 아니다. 만약 pins에 대한 reload가 1%이상이 되면, library cache miss를 줄이도록 하여야 한다.
그러나 이 view에서는 namespace별로 다른 통계값을 보여주지만, 실제 namespace별로 tuning하기란 매우 어렵다. 그래서 실제로 shared pool을 점검하는 것은 위와 같이 namespace별로 보기 보다는 다음과 같이 전체의 합을 확인한다.
SQL> select sum(pins), sum(reloads)
from v$librarycache;
SUM(PINS) SUM(RELOADS)
———- ————
177678 10
library cache miss를 줄이기 위해서는 기본적으로 library cache를 위한 추가적인 memory를 할당하거나, SQL문장 및 다른 공유 가능한 문장들을 동일하게 작성하는 것이 도움이 된다.
공유가능한 memory를 증가시키는 것은 shared_pool_size parameter만 증가시키면 된다. 그러나 이 값을 너무 증가시켜 user가 사용하여야 할 memory의 paging이나 swapping을 발생시켜서는 안된다.
SQL문장을 가능한 공유하기 위해서는 SQL문장에서 space, 대소문자, bind변수 등 문장이 완벽하게 동일할 때 공유하게 된다. 이것은 이후 SQL문의 공유 부분에서도 자세히 언급된다.
shared pool의 한 부분인 dictionary cache에 대한 통계 정보는 v$rowcache view를 통해 확인가능하다. 다음과 같은 조회결과 성능에 문제가 있다고 판단되면 (hitratio가 90%이하)shared pool size를 늘려야 한다.
SQL> select sum(gets)/(sum(gets)+sum(getmisses)) from v$rowcache;
row cache에 대한 hit ratio가 높은 것이 바람직하나, V$SGASTAT의 값 중 ‘dictionary cache’와 ‘free memory’에 대한 값을 조금 더 지속적으로 검토해 보아야 한다. 만약 ‘dictionary cache’가 상대적으로 변경이 거의 없고, ‘free memory’도 크고 변동이 별로 없다면, user가 object를 지우고 다시 만들거나 grant를 변경하는 등의 작업으로 인해 이후 row cache에 대한 hit ratio가 나빠질 가능성도 있기 때문이다.
-
Latch Contention 확인
V$LATCH
v$latch view를 조회해보면, 어느 latch가 가장 hit ratio가 나쁜지를 알 수 있으며, 또한 sleep을 제일 많이 일으키는지를 확인할 수 있다. 여기에서 sleep의 수가 더욱 중요한데 만약 library cache latch가 sleep의 수가 많다면, shared pool의 관리에 문제가 있다고 판단할 수 있다. 단 이 view는 조회한 순간의 latch에 대한 정보가 아니라 database가 startup된 후에 누적된 값인 것을 주의하여야 한다.
V$SESSION_WAIT
성능이 늦어진다고 판단되는 순간에 v$session_wait를 조회해 보면, latching에 문제가 있는지 있다면 어느 latch가 문제인지를 확인할 수 있다. 만약 library cache latch를 기다리는 process가 3이나 4이상으로 값이 크다면, latch에 대한 관리가 필요하다고 볼 수 있다.
아래의 query를 이용하도록 한다.
select count(*) from v$session_wait w, v$latch l
where w.wait_time=0
and w.event = ‘latch free’
and w.p2 = l.latch#
and l.name like ‘library%’;
select * from v$session_wait
where evne != ‘client message’
and event not like ‘%NET%’
and wait_time=0
and sid > 5;
이러한 latch의 contention을 줄이기 위해서는 shared pool내에 fragmentation을 감소시키고, 공유는 증가시키되 parse는 감소하는 등의 방법이 있다. 그 외에도 도움이 될 만한 initial parameter들이 존재하는데, 아래에서 각각에 대해 좀 더 자세히 기술하고 있다.
-
ORA-4031
shared memory의 연속된 공간을 할당하고자 할 때, 필요한 공간이 없으면, 현재 pin되어 있지 않은 모든 object들을 flush시키면서 빈 공간들을 merge시켜 필요한 공간을 확보하려 한다. 그런데 모든 object들을 shared pool에서 flush시킨 후에도 필요한 연속된 공간을 얻지 못하면 ORA-4031이 발생하는 것이다. 이 오류가 운영 중에 발생하면, database를 restartup해야 하는 상황이 되는 경우가 많으므로 미리 분석하고 대비할 필요가 있다. 아래에서 도움이 될 만한 사항들을 점검하여 본다.
event 4031
ORA-4031 오류가 발생하면 trace file이 생기도록 하기 위해 다음과 같이 event를 init.ora file에 설정할 수 있다.
event = “4031 trace name errorstack, level 4”
이렇게 하면 ORA-4031 오류가 발생할 때의 state object에 대한 dump를 발생시킨다. dump file내의 ‘load=X’부분과 ‘name=’부분을 확인하고 이 오류가 발생할 때 object가 shared pool에 load중이었는지를 확인할 수 있다. 만약 object가 load중이었다면, 이 ‘name=’ 부분에 나타난 object의 load가 문제의 원인이며 이 object는 shared pool에 keep되어지는 것이 바람직하다.
[참고]Oracle 7.2부터는 package나 function, procedure와 같은 library unit이 shared pool상에 반드시 연속된 공간을 잡지 않아도 되어 ORA-4031이 많이 줄어들었다.
실제 test결과 같은 형태의 procedure에 대해서 같은 문장을 반복하여 기술하여 source크기만 증가시킨 경우 100개 이상의 chunk를 사용하던 procedure가 source를 줄인 후 6개의 chunk만을 사용하는 것을 확인하였다.
그러므로, 만약 7.3에서 이 오류가 발생한다면 이것은 이미 shared pool의 90%이상은 사용된 것을 의미하는 경우가 많으며, 이러한 경우에는 shared pool의 크기를 늘려주는 것이 최선이다.
X$KSMLRU
x$ksmlru이라는 fixed table은 shared pool에 cache되기 위해 다른 object를 밀어낸 allocation들에 대한 정보를 담는다. 이 table은 무엇이 memory에 많은 공간을 차지하면서 할당되었는지를 알려 주는데, 한번 조회하고 나면 조회된 정보를 table에서 지워진다.
중요한 column의 의미를 간단히 정리하면 다음과 같다.
KSMLRCOM: allocation에 대한 type을 기술한다.
‘MPCODE’나 ‘PLSQL%’과 같은 내용이 포함되어 있다면, 큰 PL/SQL object가 shared pool에 load된 것이므로 이 PL/SQL object를 shared pool내에 ‘keep’ 시키는 것을 고려해 보아야 한다.
만약 MTS로 운영중이고 이 컬럼의 값이 ‘Fixed UGA’와 같은 것이라면, init.ora file내의 open_cursors값이 너무 크게 설정되어 있는 것이므로, 줄일 필요가 있다.
[참고] bug210682
bug210682는 status가 not a bug이며, open_cursors에 의해 1이 증가될 때마다 약 25 bytes를 fixed UGA를 사용하므로 open_cursors를 너무 크게 하면 memory사용에 문제가 있다고 되어있다. bug은 아니다.
KSMLRSIZ :할당된 연속된 memory의 크기이다. 이 값이 5K가 넘어가면 문제가 있다고 보고, 10K가 넘어가면 심각한 문제가, 20K가 넘어가면 매우 심각한 문제를 야기할 수 있으므로 주의가 필요하다.
KSMLRNUM :이 object의 할당으로 인해 deallocate된 object의 갯수를 나타낸다.
KSMLRHON :load된 object의 이름을 가지고 있다.
KSMLROHV :load된 object의 hash value를 나타낸다.
KSMLRSES :이 object를 load한 session의 SDDR값이다.
X$KSMSP
datafile내의 free space를 확인하는 dba_free_space view와 같이 shared pool내의 free space와 flush할 수 있는 freeable space에 대한 조각을 확인할 수 있는 view는 SYS.X$KSMSP이다. ORA-4031이 발생하는 경우 V$SGASTAT만으로는 shared pool의 전체 free space만을 확인할 수 밖에 없으나 이 view를 통해서는 space 조각에 대한 정보도 얻을 수 있어 매우 유용하다. x$ksmsp는 다음과 같은 컬럼을 가지고 있으며, 할당된 chunk 하나 당 하나의 row가 생성된다.
KSMCHCOM :chunk에 대한 속성을 나타내는 간단한 text comment
KSMCHSIZ :chunk의 크기
KSMCHPTR :memory상에서 위치에 대한 hex값
KSMCHCLS :chunk의 class
“perm”: permanent, “free”: free, “recr” for recreatable, “freeable”: freeable
SQL> select ksmchcls, max(ksmchsiz), sum(ksmchsiz)
from x$ksmsp
group by ksmchcls;
KSMCHCLS MAX(KSMCHSIZ) SUM(KSMCHSIZ)
——– ————- ————-
free 3451712 3740800
freeabl 103936 11809736
perm 4636672 4636672
recr 65344 1226664
-
Object를 shared pool에 KEEP
크기가 큰 PL/SQL의 경우 ORA-4031을 일으키거나, 이미 load된 allocation들을 해제하는 등의 문제를 야기시킬 수 있다. 그러한 경우 문제가 될 만한 PL/SQL object를 shared pool에 올려 놓고 LRU방식에 의해 밀려 나가지 않고 항상 keep시키기 위해 dbms_shared_pool package를 사용할 수 있다. 이 package는 dbmspool.sql에 정의되어 있으며, 예를 들어 다음과 같이 사용하면 된다.
SQL>execute dbms_shared_pool.keep(‘SYS.STANDARD’);
STANDARD, DBMS_STANDARD, DIUTIL과 같이 크기가 큰 object들이 이와 같이 keep시켜야 하는 대상이 되며, 이 명령은 db가 startup된 후 다른 할당이 이루어지기 전에 바로 수행하여야 한다.
dbms_shared_pool package는 7.0부터 만들어졌으며, 7.1.5까지는 package만 keep 시킬 수 있었다.그러나 7.1.6부터는 standalone procedure, function, cursor 등도 keep이 가능해 졌으며, 7.3부터는 trigger가 7.3.3.1부터는 sequence도 가능하다.
[참고] 이미 언급한 바와 같이 7.2부터는 하나의 연속된 공간이 아닌 조각으로 load가 가능하기 때문에 이 package에 대한 필요성이 많이 줄어들었다.
-
공유 증가
parse나 execute단계에서 원하는 문장이 이미 library cache내에 들어 있을 확률을 높이기 위한 중요한 방법 중 하나는 가능한 한 sql문장을 똑같이 작성하는 것이다. space, 대소문자를 비롯해 모든 문장이 똑같아야만 같은 문장이 공유가 된다.
예를 들어, sql문장의 table이름에 항상 schema이름을 붙여 사용하게 되면, 여러 database user가 같은 sql문을 자주 사용하는 경우에 도움이 되며, 그 외에도 아래와 같이 상수대신 변수를 사용하는 것도 공유를 증가시키기 위한 한 방법이 될 수 있다.
예를 들어 다음과 같은 문장이 있다고 하자.
select * from dept where deptno=10;
select * from dept where deptno=20;
이 문장을 select * from dept where deptno=:dno;
과 같이 bind variable을 사용한 하나의 문장으로 대치될 수 있다.
[참고] Oracle7.2까지 이렇게 변수를 사용하는 겨우 = 비교가 아닌 대소비교인 경우에는 전체의 25%를 search한다고 판단하여 cost based optimizer가 full table scan을 하는 경우가 있으므로 주의하여야 한다.
-
parsing이 적게 발생하도록 유도
library cache latch에 대한 load를 줄이는 또 하나의 방법은 parse call을 줄이는 것이다. 이미 parsed code가 shred pool에 cache되어 있는 상태라 하더라도, parse call자체가 권한 check 를 포함한 여러가지 부하가 많다. 이러한 parsing을 줄이는 방법은 precompiler에서 HOLD_CURSOR=TRUE로 지정하는 것이다. 단, 자주 실행되지 않는 문장을 위해 무조건 library cache내에 open cursor형태로 두는 것은 바람직하지 않으므로, 다음과 같은 조회를 통해 parse call이 많은 문장을 확인하여 필요한 program만 이 option을 사용하는 것이 바람직하다.
SQL> select sql_text, parse_calls, executions from v$sqlarea
where parse_calls > 100 and executions < 2*parse_call;
system에 대한 전체 parsing 요청 횟수는 다음과 같이 조회 가능하며, 이 값이 약 1초당 10번 이상 증가한다면 문제가 있다고 볼 수 있다.
SQL> select name, value from v$sysstat where name = ‘parse count’;
-
CURSOR_SPACE_FOR_TIME
이 parameter의 값을 TRUE로 하면, shared SQL area의 object를 참조하는 open cursor가 존재하는 한 해당 object를 항상 shared pool에 keep 시키게 된다. 각 active cursor의 SQL area가 memory에 항상 존재하기 때문에 수행 속도는 향상되지만, 그만큼 많은 memory를 차지하기 때문에 이것은 memory가 충분하고 OS의 page fault가 거의 없을 때만 TRUE로 설정하도록 한다.
이 parameter는 cursor를 수행하고 난 뒤에도 완전히 수행하고 끝나기 전까지는 private SQL area에서 cursor 정보를 해제하지 않기 때문에 cursor할당과 초기화 시간은 줄이게 된다.
-
SESSION_CACHED_CURSORS
이 parameter는 7.1까지만 사용하던 것으로, 하나의 session동안 open된 상태로 cache에 유지하고자 하는 cursor의 갯수를 지정한다.
-
CLOSE_CACHED_OPEN_CURSORS
PL/SQL을 사용할 때, 그 안의 cursor들이 memory에 cache되어 있는데, 이 cursor 들이 commit시에 자동으로 close되도록 하려면 TRUE로 설정하면 된다. default는 FALSE이며, latch bottleneck이 발생하는 경우에는 default로 유지하여야 하나, 이렇게 되면 UGA부분은 더 많이 사용된다.
-
FORMS 4
SQL*Forms version 4는 bind variable을 많이 사용하여 dynamic sql을 적게 생성시킴으로써, shared pool에 load해야 하는 부분을 줄였다.
-
Reserved Shared Pool
매우 바쁜 시스템인 경우 shared pool내에서 많은 fragmentation으로 인해서, 연속된 공간을 찾는 것이 어려운 경우가 있다. 이러한 경우를 위해서 Oracle 7.1.5부터 shared pool내에 일정 공간을 확보해 놓고 큰 공간의 할당이 필요한 경우만 사용하도록 reserved memory를 지정할 수 있다. 이와 관련된 두개의 initial parameter는 다음과 같다.
-
shared_pool_reserved_size
큰 object의 할당을 위해 별도로 확보해 두는 공간의 크기를 지정한다.
단위: bytes
기본값: 0 (reserved list를 사용하지 않음을 나타낸다.)
최소: shared_pool_reserved_min_alloc (shared_pool_resrver_size가 0일때는 의미가 없다)
최대: 1/2 shared_pool_size
-
shared_pool_reserved_min_alloc
reserved memory내에 할당할 수 있는 최소 크기를 지정한다. 이보다 작은 것은 reserved space에 할당할 수 없으며, 큰 할당의 경우에도 일단 shared pool내의 free list에서 필요한 공간을 찾아보고 없는 경우 reserved space에 할당하게 된다.
단위: bytes
기본값: 5000
최소값: 5000
최대값: shred_pool_reserved_size
-
shared pool의 flush에 대한 제어
ORA-4031이 발생하는 경우, 이 오류가 발생하기 전에 이미 unpin된 object는 flush시키면서 요구하는 space를 찾고자 시도한다. 모든 object를 flush한 후에도 원하는 공간을 찾지 못하는 경우에 ORA-4031이 발생하는 것이다.
이러한 경우에 shared pool내에 이미 cache된 object들을 flush시킴으로써, 시스템의 성능 저하를 야기할 수 있다. 그래서 Oracle7.1.5부터 dbms_shared_pool package내에 aborted_request_threshold라는 procedure를 제공하여 지정된 thresh hold값 이상이 되는 할당이 요구된 경우에만 flush를 수행하도록 할 수 있다. 이 threshold보다 작은 값에 대해서는 unpin 상태인 object를 flush하기 전에 오류를 야기하게 된다.
-
V$SHARED_POOL_RESERVED view를 이용한 tuning
shared_pool_reserved_size의 초기값: shared_pool_size의 10%정도가 적당하다.
shared_pool_reserved_min_alloc의 초기값: default인 5000 bytes정도가 적당하다.
shared_pool_reserved_size의 tuning
memory가 충분한 경우 가능한 SGA를 늘려서
REQUEST_MISS = 0
가 되면 최상이다.
그러나 OS memory가 한정되어 있는 경우, 목표는 아래와 같다.
REQUEST_FAILURES=0이거나 증가되지 않는다.
LAST_FAILURE_SIZE > shared_pool_reserved_min_alloc
AVG_FREE_SIZE > shared_pool_reserved_min_alloc
(1) shared_pool_reserved_size가 너무 작은 경우
만약 위의 기준들이 전혀 만족되고 있지 않다면, shared_pool_reserved_size를 증가시키고, 같은 크기만큼 shared_pool_size도 증가시킨다. 또는 shared_pool_size는 증가시키지 않고 shared_pool_reserved_min_alloc값을 증가시킨다.
(2) shared_pool_reserved_size가 너무 큰 경우
이때, REQUEST_MISS=0이거나 증가하지 않고 FREE_MEMORY가 shared_pool_reserved_size의 50% 이상이라면 shared_pool_reserved_size가 너무 크게 설정된 경우이므로 이때는 shared_pool_reserved_size나 shared_pool_min_allock값을 감소시킨다.
(3) shared_pool_size가 너무 작은 경우
REQUEST_FAILURES 가 0보다 크거나 증가하는 경우
LAST_FAILURE_SIZE < shared_pool_reserved_min_alloc을 만족하면
이때는 shared_pool_size가 작은 경우이므로
shared_pool_size를 증가시키거나
shared_pool_reserved_size와 shared_pool_reserved_min_alloc값을 감소시킨다.
-
-
Large Pool
Oracle8.0에서 large pool이라는 새로운 SGA내의 구성이 도입되었다. large pool이란 shared pool과 유사하나 실제 shared pool내의 일부분을 사용하는 것은 아니고 SGA내에 직접 할당하며, 이 pool을 사용할 수 있는 작업들을 제한하고 있다.
Oracle8에서 large pool을 사용하는 주요 목적은 다음과 같이 두가지로 볼 수 있다.
-
MTS connection에서 session 정보, 즉 UGA를 할당하기 위해서
-
sequential file IO의 buffering을 위해서 (예를 들어, multiple IO slave를 사용하는 경우의 recovery)
MTS connection이 large pool을 사용하는 경우, 일단 fixed UGA라고 하는 부분은 shared large pool을 사용하고, 나머지 session memory (UGA)는 large pool에 할당된다. 만약 large pool이 충분하지 않으면 ORA-4031이 발생한다.
large pool을 지정하기 위해서는 init.ora file내에 large_pool_size라는 parameter를 사용하고, larlge_pool_min_alloc parameter는 이 large pool에 할당될 최소한의 memory chunk size를 제한한다. 이 large_pool_min_alloc의 값이 클수록 large pool의 fragmentation은 줄어든다. 만약 이 parameter를 지정하지 않으면 large pool은 사용하지 않는다. 그러나 다음 중 하나라도 만족되는 상황에서는 large pool에 관한 parameter가 설정되어 있지 않다 하더라도 Oracle이 자동으로 필요한 large pool을 계산하여 할당하여 사용한다.
-
parallel_automatic_tuning = true
-
parallel_min_servers=n
-
dbwr_io_slaves=n
large pool size에 대한 계산은 다음 값에 의해서 결정된다.
-
parallel_max_servers
-
parallel_threads_per_cpu
-
parallel_server_instances
-
mts_dispatchers
-
dbwr_io_slaves
이러한 default에 의해 계산된 large pool이 너무 크게 되면, performance에 문제가 생기거나 db startup이 안될 수 있다. 그러므로 이러한 때에는 적당한 값의 large_pool_size로 지정한 후 다시 startup하여야 한다.
This is actually useful, thanks.