현상적으로 느끼는 DBMS Hang은 크게 “Very Slow Performance” 와 “Hang”으로 구분됩니다.
– Very Slow Performance
마치 Hang처럼 보여 업무가 거의 돌지 않는 것처럼 보이지만 Hang을 유발하는 Blocker가 매우 짧은 시간간격으로 지속적으로 바뀌고 매우 짧은 hang이 꼬리에 꼬리 를 물고 지속됨.
– Hang
Blocker 가 Stuck된 상태를 유지하여 Waiting Session들이 전혀 일을 하지 못하는 상태 가 지속되거나 이와 유사한 형태의 Hang Chain이 유지. 예전에는 Hang 또는 Slow Performance를 분석하기 위해 Hang Aanalyze와 Systemstate Dump를 Manual하게 수행하여 오라클사에 분석을 의뢰했습니다. 하지만, DBMS의 버전이 올라감에 따라 Hang 분석에 대한 자동화 기술이 발전하여 11.2.0.2 이상에서는 신뢰할 만한 자동 Hang분석과 해결이 이루어지고 있습니다.
Hang Manager(HM)는 10gR2부터 탑재되기 시작했고, 버전이 올라감에 따라 Wait Event와 함께 발전 해 가고 있습니다. Hang Manager의 주된 역할은 신뢰할 만한 Hang 상태를 Detect하고 문제를 해결 하는 것입니다. Hang Manager가 Detect하는 Hang Type은 다음과 같습니다.
- Enqueue wait events
- Latch wait events
- Stable terminal wait events
- Buffer cache wait events
- Log writes wait events
- Cursor wait events
- Ges wait events
- Gcs wait events
- Gc wait events
Hang Manager는 Local Hang에 대해서는 매 3초마다(_local_hang_analysis_interval_secs), Global Hang에 대해서는 매 10초마다(_global_hang_analysis_interval_secs) hang분석을 수행하여 Hang Cache라고 불리우는 메모리 공간에 해당 정보를 저장합니다. 11gR2부터는 Hang Signature Cache(HSC)라는 좀 더 발전 된 형태의 Hang Cache 구조를 갖습니다. Hang Cache에 대한 정보는 v$wait_chains 을 통해 조회할 수도 있고 v$session 과 v$session_blockers 에도 정보가 제공됩니다.

Hang Manager는 dia0 백그라운드 프로세스(instance_number가 가장 작은 instance의 dia0가 master dia0임)에 의해 Hang Cache에 있는 정보를 분석하여 Hang인지를 판단하며 Hang Resolution Huristics 의해 root가 되는 session 또는 process를 Kill 하기도 하고 Ignore하기도 합니다.
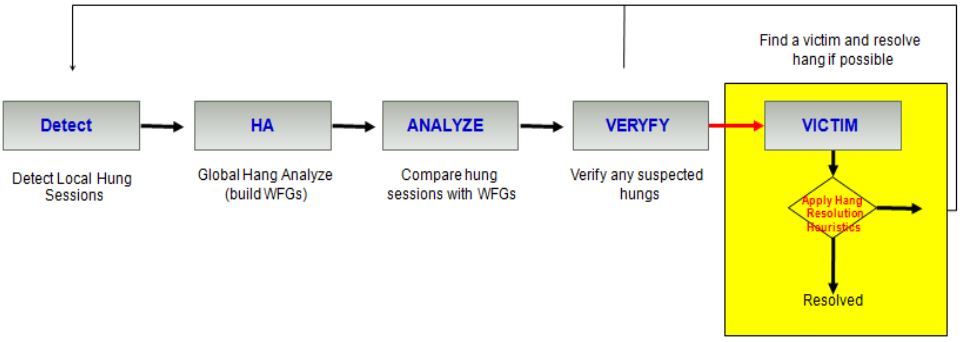
ORACLE HANG MANAGER 동작 절차

Dia0가 Wiat Session들을 발견하면 바로 v$wait_chains 에 해당 정보들이 보입니다. 그리고 위의 Phase 대로 진행하여 Hang으로 의심되거나(Suspected), 확정(Verify)되면 Trace를 떨구고, Resolution가능한 Hang일 경우 Root Session을 Kill합니다.

Dia0가 Wiat Session들을 발견하면 바로 v$wait_chains 에 해당 정보들이 보입니다. 그리고 위의 Phase 대로 진행하여 Hang으로 의심되거나(Suspected), 확정(Verify)되면 Trace를 떨구고, Resolution 가능한 Hang일 경우 Root Session을 Kill 합니다.
Hang Manager의 동작과 관련된 Hidden Parameters

Hang Manager에 의해 Verified된 Hang과 관련 Session정보는 v$hang_info 와 v$hang_session_info에 남겨집니다.
또는 이러한 정보는 Trace Files로 정보가 남기 때문에 향후 문제 분석에 소중한 자료로 이용됩니다.
Dia0에 의한 Trace Files는 Alert Log와 동일한 위치에 생성됩니다.
v$wait_chains을 이용한 Troubleshooting (MOD DocID 1428210.1)
dia0은 매 3초마다(global hang은 매 10초마다) hanganalyze 수행정보를 Hang Cache라는 메모리 공간에 저장하는데 v$wait_chains 을 통해 분석을 하여 Final Blocker가 어느 세션이고 어떤 wait event인지를 확인할 수 있습니다.
DB Hang 상태 점검 쿼리 (MOD DocID 1428210.1)
SELECT chain_id, num_waiters, in_wait_secs, osid, blocker_osid, substr(wait_event_text,1,30) FROM v$wait_chains;

DB Hang 현상이 발생되었고 현재는 Hang이 풀리거나 해결된 상태라면,
- Alert Log를 통해 Hang관련 Incident가 발생되었는지 확인
- Dia0 프로세스에 의한 Dump(Trace Files) 분석
- 선택적으로(예: action plan으로 현업등과 협의가 된 상태) Hanganalyze 와 Systestate & Dump 를 수행
- 필요시 SR 진행 및 관련 정보 Upload
Hang Manager Tracing
HM이 Detect한 Hang은 dia0 trace 파일에 정보를 남깁니다. Dia0 trace파일은
- <SID>_dia0_<PID>_base_n.trc (dia0 Base Trace File)
- <SID>_dia0_<PID>.trc (dia0 Default Trace File)
와 같은 형태로 되어 있고, 여기에서 n은 1부터 5(_hang_base_file_count)까지 증가하며 circular 방식으로 순차적으로 돌아가면서 파일이 씌여집니다. 이는 HM에 의한 과도한 양의 Trace파일이 생성되는 것을 예방하기 위함입니다. 한 개의 base trace파일의 크기는 10,000,000 bytes(_hang_base_file_space_limit) 입니다.
※ DB Instance가 start되면서 <SID>_dia0_<PID>.trc 라는 일반적인 Trace 파일이 생성되지만 HM은 Base Trace File로 옮겨 Tracing하기 시작합니다. Hang 분석은 Base Trace File부터 시작하지만 경우에 따라서 는 Default Trace File에 정보를 남기기도 합니다.