0.
인덱스는 사용자가 임의적으로 생성 변경이 가능한 데이터 베이스에 저장가능한 물리적인 구조입니다. 하지만 인덱스는 단순하게 색인이라는 개념에 앞서 옵티마이저가 실행계획을 수립할 때 최적의 경로를 찾도록 하는 ‘전략적 요소’라는 시각에서 접근하여야 합니다. 인덱스가 존재하지 않는 다면 테이블에서 행들은 특정한 순서에 따르지 않고 저장됩니다.
행이 처음 삽입될 때 사용자는 행이 보관될 물리적인 위치를 선택할 수 없습니다. 이것은 테이블에서 특정한 행을 찾기 위해서는 찾고자 하는 행을 만날 때까지 순차적으로 검색해야 함을 의미하기도 합니다. 또한, 지정한 조건에 일치하는 행을 찾았다고 해도 테이블의 논리적인 끝에 도달하기 전까지는 검색을 멈출 수 없습니다. 일치하는 행을 찾았다고 해도 조건에 맞는 행이 더 이상 없다는 확신이 없기 때문에 계속 검색하게 됩니다.
이와 같은 정보의 검색 방식을 완전 테이블 검색(full table scan)이라 부르며, 완전 테이블 검색을 수행하기 위해서는 하이 워터마크(high water mark)라 불리는 테이블의 논리적 끝에 이를 때까지 테이블의 모든 블록을 로드하고 읽어야 합니다.
인덱스의 효율성을 위해 테이블에 새로운 행을 삽입하기 위해서는 인덱스에도 대응되는 항목을 추가해야 합니다. 즉, 한 번이 아닌 두 번의 삽입 작업이 필요하다는 것이며, 결과적으로 인덱스의 존재 때문에 삽입 작업의 속도가 떨어지며 삽입 작업뿐만 아니라 인덱스에 영향을 주는 갱신이나 삭제 작업에도 역시 인덱스를 최신의 것으로 유지하는 부가적인 처리가 필요하게 됩니다. 즉, 일반적으로 인덱스는 DML(INSERT, UPDATE, DELETE, 쿼리)을 느리게 만들기 때문에 효율적인 인덱스 사용을 위해 인덱스를 과용하지 말아야 합니다.
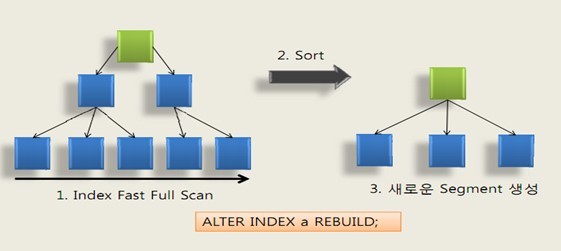
테이블로의 행이 insert 되는 것은 인덱스 구조에 상당한 변화가 생깁니다. 인덱스 구조인 트리 계층의 위쪽으로도 구조를 변화시켜 인덱스의 높이를 증가시키고 성능을 감소시키기도 합니다. 일반적으로는 인덱스의 효율을 떨어뜨리는 것은 인덱스의 높이보다는 인덱스 내의 변화 자체와 부가적인 블록을 얻는 과정입니다.
테이블의 DML작업으로 인한 데이터 갱신은 인덱스 갱신으로 이어지지 않으므로 인덱스의 최하위 계층 노드(Leaf)의 위치는 대부분 잘못된 상태로 남겨지게 됩니다. 따라서 원래의 항목을 사용되지 않도록 표시하고, 새로운 항목을 적절한 위치에 삽입하는 과정이 필요하게 됩니다. 이러한 과정을 인덱스 리빌드라고 합니다.
1.
1) Index Offline Rebuild
-Rebuild가 이루어지는 동안 DML blocking
-Rebuild가 완료될 때까지 추가적인 공간 필요(기존 Index+ 신규 Index)
-Sparse가 높고 크기가 큰
Index에 대한 Rebuild 성능은 가장 우수
*
Sparse란 인덱스 블록 전반에 걸쳐 밀도(density)가 떨어지는 현상을 말합니다.

2) Index Online Rebuild(E.E 지원)
– PK, UK는 제약조건으로 인해 인덱스 리빌드에서 제외됨
– Rebuild가 이루어지는 동안 DML 허용(단, 최초
작업과 최종 작업 단계의 짧은 시간 동안 DML Blocking 발생가능)
– Rebuild가 완료될 때까지 추가적인 공간 필요(기존 Index+ 신규 Index)
– Offline Rebuild에 비해 성능은 좋지 않음(Full table Scan, Journal Table, Merge)

2.
1) Sparse Index 조회 쿼리
(sparse Index 조회 쿼리)
select /* ordered */
u.name “Owner”,
o.name “Index”,
op.subname
“Partition”,
decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,o.subname,”)
“SubPartition”,
(1-
floor(decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.leafcnt,ip.obj#,ip.leafcnt,i.lea
fcnt)
–
decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.rowcnt
,ip.obj#,ip.rowcnt ,i.rowcnt
)
*(sum(h.avgcln)+10)
/((p.value-66-
decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.initrans,ip.obj#,ip.initrans,i.initrans
)*24)
*(1-decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.pctfree
$,ip.obj#,ip.pctfree$,i.pctfree$)/100))
)/decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.leafcnt,ip.obj#,ip.leafcnt,
i.leafcnt))
“Density”,
floor(decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.leafcnt,ip.obj#,ip.leafcnt,i.lea
fcnt)
–
decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.rowcnt
,ip.obj#,ip.rowcnt ,i.rowcnt
)
*(sum(h.avgcln) + 10)
/((p.value-66-
decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.initrans,ip.obj#,ip.initrans,i.initrans
)*24)
*(1-decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.pctfree
$,ip.obj#,ip.pctfree$,i.pctfree$)/100)))
“Extra.Block”
from
sys.ind$
i,
sys.icol$
ic,
( select
obj#,part#,bo#,ts#,rowcnt,leafcnt,initrans,pctfree$,analyzetime,flags from
sys.indpart$
union all
select
obj#,part#,bo#,defts#,rowcnt,leafcnt,definitrans,defpctfree,analyzetime,flags
from
sys.indcompart$
) ip,
sys.indsubpart$ isp,
( select ts#,blocksize value from sys.ts$
) p,
sys.hist_head$ h,
sys.obj$
o,
sys.user$ u,
sys.obj$
op
where
i.obj# = ip.bo#(+)
and ip.obj# = isp.pobj#(+)
and
decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.leafcnt,ip.obj#,ip.leafcnt,i.leafcnt)
> 1
and i.type# in (1) /* exclude special types */
and i.pctthres$ is null /* exclude IOT secondary indexes */
and decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.ts#,ip.obj#,ip.ts#,i.ts#)
=
p.ts#
and ic.obj# = i.obj#
and h.obj# = i.bo#
and h.intcol# = ic.intcol#
and o.obj# = nvl(isp.obj#,nvl(ip.obj#,i.obj#))
and o.owner# != 0
and u.user# = o.owner#
and op.obj# = nvl(ip.obj#,i.obj#)
and u.name not in
(‘SYS’,’SYSTEM’,’SYSMAN’,’XDB’,’HR’,’ODM’,’OUTLN’,’OE’,’SH’,’PM’,’SYSAUX’,’IX’,’WK_T
EST’,’PERFSTAT’,’DBSNMP’,’OLAPSYS’,’QS_CS’,’QS_CB’,’QS_CBADM’,’QS_OS’,’QS_WS’,’
QS’,’QS_ADM’,’ODM_MTR’
,’WKPROXY’,’QS_ES’,’ANONYMOUS’,’WKSYS’,’WMSYS’,’A
PEX_
030200′,’APEX_PUBLIC_USER’,’APPQOSSYS’,’BI’,’CTXSYS’,’DIP’,’EXFSYS’,’FLOWS_FILES’
,’MDDATA’,’MDSYS’,’MGMT_VIEW’,’ORACLE_OCM’,’ORDDATA’,’ORDPLUGINS’,’ORDS
YS’,’OWBSYS’,’OWBSYS_AUDIT’,’SCOTT’,’SI_INFORMTN_SCHEMA’,’SPATIAL_CSW_AD
MIN_USR’,’SPATIAL_WFS_ADMIN_USR’,’XS$NULL’)
group
by
u.name,
o.name,
op.subname,
decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,o.subname,”),
decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.rowcnt
,ip.obj#,ip.rowcnt ,i.rowcnt
),
decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.leafcnt,ip.obj#,ip.leafcnt,i.leafcnt),
decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.initrans,ip.obj#,ip.initrans,i.initrans
),
decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.pctfree$,ip.obj#,ip.pctfree
$,i.pctfree$),
p.value
having
(1-
floor(decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.leafcnt,ip.obj#,ip.leafcnt,i.lea
fcnt)
–
decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.rowcnt
,ip.obj#,ip.rowcnt ,i.rowcnt
)
*(sum(h.avgcln)+10)
/((p.value-66-
decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.initrans,ip.obj#,ip.initrans,i.initrans
)*24)
*(1-decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.pctfree
$,ip.obj#,ip.pctfree$,i.pctfree$)/100))
)/decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.leafcnt,ip.obj#,ip.leafcnt,
i.leafcnt)
) <= 0.75
And
floor(decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.leafcnt,ip.obj#,ip.leafcnt,i.lea
fcnt)
–
decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.rowcnt,ip.obj#,ip.rowcnt,i.rowcnt)
*(sum(h.avgcln) + 10)
/((p.value-66-
decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.initrans,ip.obj#,ip.initrans,i.initrans
)*24)
*(1-decode(nvl(isp.obj#,nvl(ip.obj#,i.obj#)),isp.obj#,isp.pctfree
$,ip.obj#,ip.pctfree$,i.pctfree$)/100))
) > 1000
order
by 6 desc,5
/
2) Index rebuild 명령어
SQL>Alter
index ‘owner.Index_name’ rebuild; <– 기본 구문
작업이 완료된 후 sparse Index 조회하는 쿼리를 수행해서 대상 Index 가 조회 되는 지 확인합니다.
또는 볼드체 부분의 수치를 조정하여 조회를 해봅니다.