- 분산
데이터베이스의
개요
- 여러
곳으로
분산되어
있는
데이터베이스를
하나의
가상
시스템으로
사용할
수
있도록
한
데이터베이스 - 논리적으로
동일한
시스템에
속하지만, 컴퓨터
네트워크를
통해
물리적으로
분산되어
있는
데이터들의
모임, 물리적 Site 분산, 논리적으로
사용자
통합/공유 - 분산
데이터베이스는
데이터베이스를
연결하는
빠른
네트워크
환경을
이용하여
데이터베이스를
여러
지역
여러
노드로
위치시켜
사용성/성능
등을
극대화
시킨
데이터
베이스
-
분산
데이터베이스의
투명성(Transparency)
분산데이터베이스가
되기
위해서는 6가지
투명성을
만족해야
한다.
- 분할
투명성(단편화) : 하나의
논리적 Relation이
여러
단편으로
분할되어
각
단편의
사본이
여러 site에
저장
- 위치
투명성 : 사용하려는
데이터의
저장
장소
명시
불필요, 위치정보가 System Catalog에
유지되어야
함
- 지역사상
투명성 : 지역 DBMS와
물리적 DB사이의 Mapping 보장. 각
지역시스템
이름과
무관한
이름
사용
가능
- 중복
투명성 : DB 객체가
여러 site에
중복
되어
있는지
알
필요가
없는
성질
- 장애
투명성 : 구성요소(DBMS, Computer)의
장애에
무관한 Transaction의
원자성
유지
- 병행
투명성 : 다수 Transaction 동시
수행시
결과의
일관성
유지, Time Stamp, 분산 2단계 Locking을
이용
구현
- 분할
-
분산
데이터베이스의
적용
방법
및
장단점
가. 분산
데이터베이스
적용방법
- 단순히
분산
환경에서
데이터베이스를
구축하는
것이
목적이
아닐, 업무의
특징에
따라
데이터베이스
분산구조를
선택적으로
설계하는
능력이
필요. - 데이터베이스
분산
설계라는
측면보다는
데이터베이스
구조설계(아키텍쳐)라는
의미로
이해하는
것이
좋음
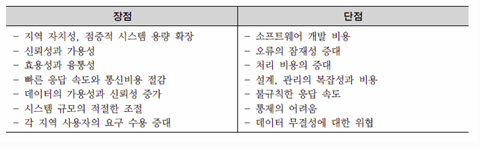
나. 분산
데이터베이스
장단점

-
분산
데이터베이스의
활용
방향성
업무적인
특징에
따라
분산
데이터베이스를
황용하는
기술이
필요하다.

- 데이터베이스
분산구성의
가치
-
데이터를
분산
환경으로
구성하였을
때
가장
핵심적인
가치는
통합된
데이터베이스에서
제공할
수
없는
빠른
성능을
제공한다는
점
-
분산
데이터베이스의
적용
기법
가. 테이블
위치
분산
- 테이블의
위치를
각각
다르게
위치시키는
것 -
예를
들면, 자재품목
테이블은
본사에서
생산제품
테이블은
각각
지사로
분산
시키는
것
나. 테이블
분할(Fragmentation) 분산
Row 단위로
분리하는
수평분할과
컬럼
단위로
분할하는
수직분할이
있다.
-
수평분할 : 테이블을
특정
컬럼의
값을
기준으로 Row를
분리한다. 분할된
데이터는
서로
배타적으로
존재하며, 데이터를
한군데
집합시켜
놓아도 Primary Key에
의해
중복이
발생되지
않는다.
-
수직분할 : 테이블
컬럼을
기준으로
컬럼을
분리한다.각각의
테이블에는
동일한 Primary Key구조와
값을
가지고
있어야
한다. 데이터를
한군데
집합시켜
놓아도
동일한 Primary Key는
하나로
표현하면
되므로
데이터
중복은
발생되지
않는다.
다. 테이블
복제(Replication) 분산
마스터
데이터베이스에서
테이블의
일부의
내용만
다른지역, 서버에
위치시키는
부분복제가
있고
마스터
데이터베이스의
테이블의
내용을
다른지역, 서버에
위치시키는
광역복제가
있다.
-
부분복제 : 통합된
테이블을
한군데(본사)에
가지고
있으면서
각
지사별로는
지사에
해당된 Row를
가지고
있는
형태. 지사에
존재하는
데이터는
반드시
본사에
존재하게
된다. 보통
지사에서
데이터가
먼저
발생하고
본사에
데이터는
지사에
데이터를
이용하여
통합하여
발생된다. 각
지사에서
데이터
처리가
용이할
뿐만
아니라
전체
데이터에
대한
통합처리도
본사에
있는
통합
테이블을
이용하게
되므로
여러
테이블에
조인이
발생하지
않는
빠른
작업
수행이
가능해진다.각
지사별로
업무수행이
용이하고
본사에
있는
데이터를
이용하여
보고서를
출력하거나
통계를
산정하는
등
다양한
업무형태로
이용
가능하다. 다른
지역간의
데이터를
복제하는데
많은
시간이
소요되고
서버에
부하가
가기
때문에
실시간
처리로
복사하는
것보다는
야간에
배치
작업에
의해
수행되는
경우가
많다.

-
광역복제 : 통합된
테이블을
한군데(본사)에
가지고
있으면서
각
지사에도
본사와
동일한
데이터를
모두
가지고
있는
형태. 본사와
지사
모두
동일한
정보를
가지고
있으므로
본사나
지사나
데이터처리에
특별한
제약을
받지
않는다. 예를
들어
본사에서
코드테이블에
데이터에
대해
입력, 수정, 삭제가
발생하고
각
지사에서는
코드데이터를
이용하는
프로세스가
발생한다. 즉
본사에서는
데이터를
관리하고
지사에서는
이
데이터를
읽어
업무프로세스를
발생시키는
것이다.
라. 테이블
요약
분산
동일한
테이블
구조를
가지고
있으면서
분산되어
있는
동일한
내용의
데이터를
이용하여
통합된
데이터를
산출하는
방식의
분석요약과
분산되어
있는
다른
내용의
데이터를
이용하여
통합된
데이터를
산출하는
방식의
통합요약이
있다.
-
분석
요약 : 각
지사별로
존재하는
요약정보를
본사에
통합하여
다시
전체에
대해서
요약정보를
산출하는
분산방법이다. 예를
들어
제품별
판매실적이라는
테이블이
존재한다고
가정하자. 각
지사에서는
취급제품이
동일하다. 지사별로
판매된
제품에
대해서
지사별로
판매실적이
관리된다. 지사1과
지사2에도
동일한
제품이
취급이
되므로
이를
본사에서
판매실적을
집계할
경우에는
통합된
판매실적을
관리할
수
있는
것이다.
-
통합요약 : 각
지사별로
존재하는
다른
내용의
정보를
본사에
통합하여
다시
전체에
대해서
요약정보를
산출하는
분산방법이다. 지사에서
산출한
요약정보를
한군데
취합하여
보여주는
형태.
-
분산
데이터베이스를
적용하여
성능이
향상된
사례

데이터베이스
분산
설계는
다음과
같은
경우에
적용하면
효과적이다.
- 성능이
중요한
사이트에
적용해야
한다. - 공통코드, 기준정보, 마스터
데이터
등에
대해
분산환경을
구성하면
성능이
좋아진다. - 실시간
동기화가
요구되지
않을
때
좋다. 거의
실시간(Near Real Time)의
업무적인
특징을
가지고
있을때도
분산
환경을
구성할
수
있다. - 특정
서버에
부하가
집중이
될
때
부하를
분산할
때도
좋다. - 백업
사이트(Disaster Recovery Site)를
구성할
때
간단하게
분산기능을
적용하면
구성할
수
있다.